
Knowledge Distillation (KD) Crash Course Notes
Notes on Knowledge Distillation Methods and Techniques
• 1 min read
Scientific ResearchFa-De-ReKnowledge Distillation
Algorithm Principles & Overview
实际终端算力有限 + 预训练大模型(参数规模每年增加 10 倍) → 需要模型压缩 + 加速推理 → 知识蒸馏(Knowledge Distillation, KD)
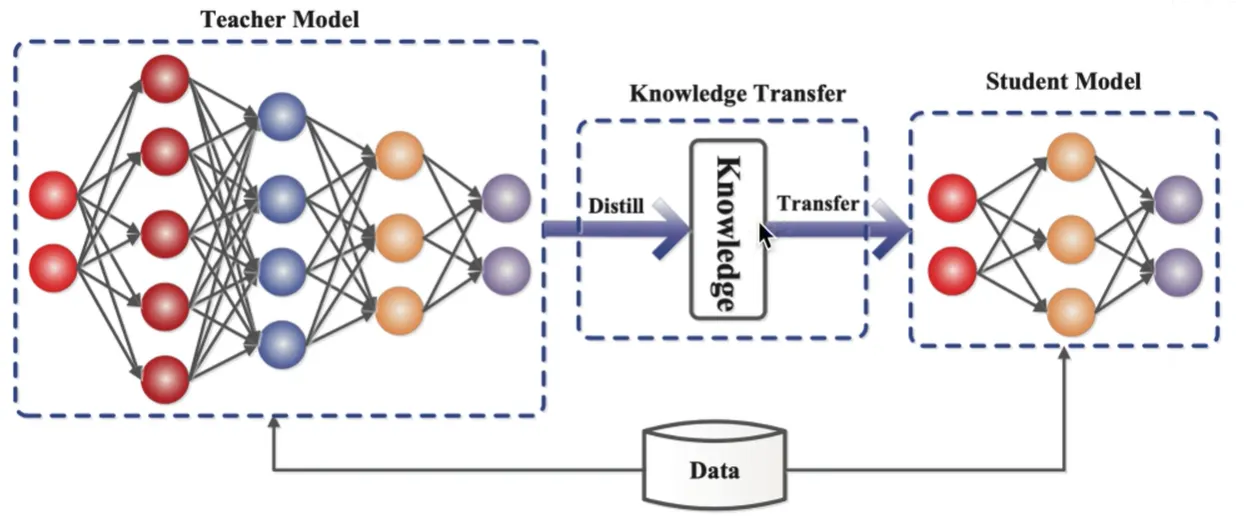
知识的表示与迁移
| 类型 | 英文 | 说明 |
|---|---|---|
| 硬标签 | Hard Labels / Ground Truth | 常规训练中使用的标签,通常以 One-hot 形式存在。它非常绝对,只告诉模型哪个是“对”的,其他全是“错”的。 |
| 软标签 | Soft Labels / Soft Targets | 由教师模型经过 Softmax 层输出的预测概率分布。不仅指出最大可能类别,还保留了其他类别的概率值。 |